
A typical problem of graph theory is to find the shortest or most optimal route from an initial point to an end point. The approach presented to this problem is to consider a directed graph, weighted (positive or negative) and using the characteristics of the DNA, by Inchrosil technology. In this way, using a device based on Inchrosil, it is possible to find the shortest or most optimal path. Let us give an example, supposing that we want to resolve the problem of Figure 1 by the lists of adjacencies and set theory.

Figure 1: Graph Example
In the graph of Figure 1, it is possible to represent as a list of adjacencies, where the nomenclature would be the following; (source vertex, edge, destination vertex), therefore, the graph would remain as follows.
- Node(s): {(s,x1,u),(s,x2,v)}
- Node(u): {(u,x3,w),(u,x7,v)}
- Node(v) : {(v,x5,t)}
- Node(w): {(w,x4,v),(w,x6,t)}
Using set theory, we can form a set with all elements of the adjacency list, i.e. the elements (vertex, edge, vertex). This set that we have formed would have premises which are enumerated below.

- If there are two elements belonging to the set, such as e1 and e2, it is observed that the end component of e1 is equal to the initial component of e2; both elements react, creating a new element, which will belong to the set.
- If there are elements which belong to the set, which contain components which are initial and final, they do not react with the rest, since they would now be solution.
- Two elements that react have a positive ratio or 1; instead two elements which do not react have a negative ratio or 0.
- The elements with initial components and that belong to the adjacency lists, once reacted do not react again.
If it is known that E is the set of elements and C is the set of components, we can see that the reaction is the following operation:
In this case, we have a set of elements belonging to the adjacencies lists, which we will denote as Element-[i], therefore, the set would initially remain in the following form.
- Element-1: {(s, x1, u)}
- Element-2: {(s, x2, v)}
- Element-3: {(u, x3, w)}
- Element-4: {(u, x7, v)}
- Element-5: {(w, x4, v)}
- Element-6: {(w, x6, t)}
- Element-7: {(v, x5, t)}
With this initial set, its elements can be analysed and it can be seen how these premises associated to the set can be fulfilled and new elements be created. In this case, it can be seen that Element-1 would react with Element-3 and Element-4, forming Element-8 and Element-9, respectively. It can also be seen that Element-2 reacts with Element-7 to form Element-10, which is now solution. After this, the set would remain as follows.
- Element-1: {(s, x1, u)} [does not react] premise 4
- Element-2: {(s, x2, v)} [does not react] premise 4
- Element-3: {(u, x3, w)}
- Element-4: {(u, x7, v)}
- Element-5: {(w, x4, v)}
- Element-6: {(w, x6, t)}
- Element-7: {(v, x5, t)}
- Element-8: {(s, x1, u, x3, w)}
- Element-9: {(s, x1, u, x7, v)}
- Element-10: {(s, x2, v, x5, t)}
In a following round, it is observed that Element-8 can react with Element-5 forming Element-11 and, that also Element-8 can react with Element-6 to form Element-12, finally, Element-9 reacts with Element-7 forming Element-13. In this round the set would be as follows.
Observing the set, it is seen that there is a single reaction, that of Element-11, which reacts with Element-7 to form Element-14. With this last reason, the set would be as follows.

- Element-1: {(s, x1, u)} [does not react] premise 4
- Element-2: {(s, x2, v)} [does not react] premise 4
- Element-3: {(u, x3, w)}
- Element-4: {(u, x7, v)}
- Element-5: {(w, x4, v)}
- Element-6: {(w, x6, t)}
- Element-7: {(v, x5, t)}
- Element-8: {(s, x1, u, x3, w)}
- Element-9: {(s, x1, u, x7, v)}
- Element-10: {(s, x2, v, x5, t)}
- Element-11: {(s, x1, u, x3, w, x4, v)}
- Element-12: {(s, x1, u, x3, w, x6, t)}
- Element-13: {(s, x1, u, x7, v, x5, t)}
Observing the set, it is seen that there is a single reaction, that of Element-11, which reacts with Element-7 to form Element-14. With this last reason, the set would be as follows.
- Element-1: {(s, x1, u)} [does not react] premise 4
- Element-2: {(s, x2, v)} [does not react] premise 4
- Element-3: {(u, x3, w)}
- Element-4: {(u, x7, v)}
- Element-5: {(w, x4, v)}
- Element-6: {(w, x6, t)}
- Element-7: {(v, x5, t)}
- Element-8: {(s, x1, u, x3, w)}
- Element-9: {(s, x1, u, x7, v)}
- Element-10: {(s, x2, v, x5, t)}
- Element-11: {(s, x1, u, x3, w, x4, v)}
- Element-12: {(s, x1, u, x3, w, x6, t)}
- Element-13: {(s, x1, u, x7, v, x5, t)}
- Element-14: {(s, x1, u, x3, w, x4, v, x5, t)}
It can be seen that the results are Element-10, Element-12, Element-13 and finally Element-14, since they have initial and final components. The operation of this previous approach, to find the solutions or paths, is performed sequentially. But in the circuit is performed in parallel form, i.e. the circuit has considered two sets; the first set C1, is formed by the elements which contain initial components and the elements that do not contain final components. The second set C2 is formed by the elements that contain final components and the elements which do not contain initial components. Both sets are encoded by Cod-Inchrosil and, stored in different strands Figure 2-10, respectively. These strands link their components by a circuiting which contains comparers Figure 2-9, forming a matrix as observed in Figure 2; in this way, they react in parallel form, obtaining a set of reactions encoded as positive (1) or negative (0). These reactions form a matrix of 0s and 1s. Therefore, there are two sets C1 and C2, which represent the two aforementioned sets and which are encoded in Inchrosil strands. On the other hand, we have a Cr, which is formed by the reactions between the elements of set C1 and C2; in this way, the reaction is redefined as the operation, where e2C2 and e1C1, then e1e2Cr, with being the reaction and the values it may take are 0 or 1. As is observed, a new element is not created in the reaction which must react, but all react at the same time and it is indicated in a matrix, with a 1 if there had been a reaction or the reaction is positive and, in contrast, with a zero if there had not been a reaction or the reaction has been negative.
Figure 2: Circuit to solve short path
Once the matrix has been obtained with the reactions of all elements with all others, this information is passed to a buffer and, by software or circuitry, path recovery algorithms are applied to it, which do not have a very high cost and are of polynomial order. If weighted graphs are considered, the weights would be stored in a memory (Inchrosil memory or another type of memory), therefore, the edges of the previous graph contain the direction and not the value of the weight, the motive why large quantities can be used for the weights and the directions have a determined length. Once the edges of the path have been found, it is only necessary to add the costs of each edge, to obtain the total cost of the path. Then with the total costs, the paths can be sorted according to sorting criteria; all of this can be performed by circuitry or software modules, which would be connected with the device. This circuit resolves the problems posed in Dijkstra's, Floyd-Warshall and Bellman-Ford's and Ford-Fulkenson's algorithms, as they can consider negative costs, etc.
The advantage of these systems is the easy incorporation in existing hardware systems, since both are based on electronics and integrated circuits. On the other hand, it is a hardware alternative for the existing calculation systems, since with the software systems they need another environment (operating system, virtual machines, etc.) to function and, instead, this device would be connected directly to the circuitry of the host device.








 represent vertex (in this case, cities) and
represent vertex (in this case, cities) and
 represent edges (roads between cities). On the other hand, graph of Figure 1
would be called ‘G’ and its encoding could be seen in Figure 3,
where A0…An
represents edges of graph and E0….En
represents cities or nodes of problem formulated.
represent edges (roads between cities). On the other hand, graph of Figure 1
would be called ‘G’ and its encoding could be seen in Figure 3,
where A0…An
represents edges of graph and E0….En
represents cities or nodes of problem formulated.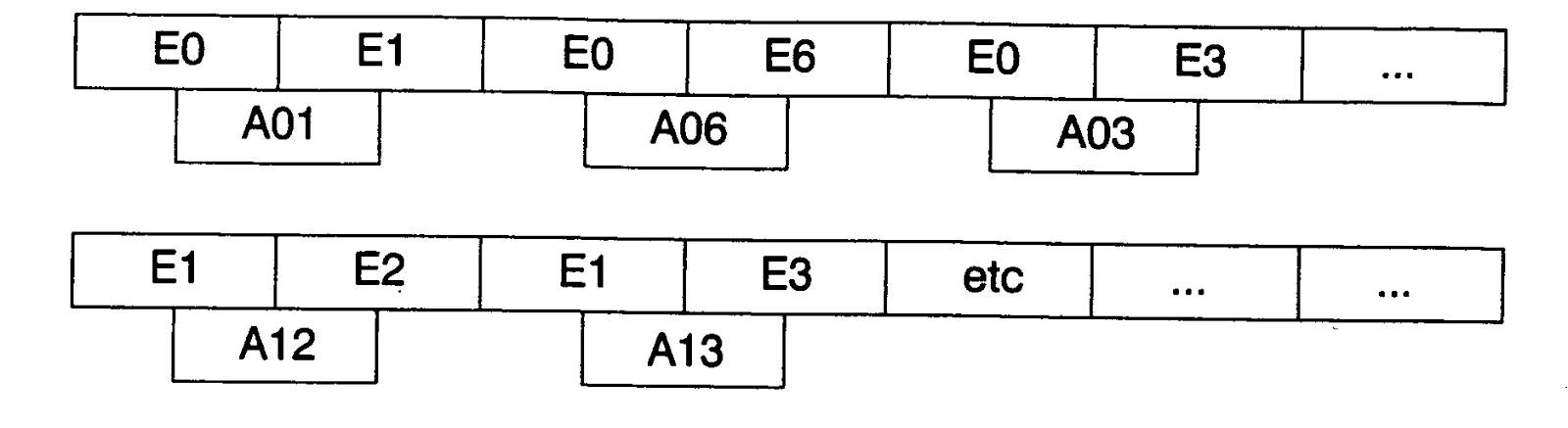



 NP.
NP.